publications
2025
- ArXiv
 Counting Through Occlusion: Framework for Open World Amodal CountingSafaeid Hossain Arib, Rabeya Akter, Abdul Monaf Chowdhury, Md Jubair Ahmed Sourov, and Md Mehedi HasanarXiv preprint arXiv:2511.12702, 2025
Counting Through Occlusion: Framework for Open World Amodal CountingSafaeid Hossain Arib, Rabeya Akter, Abdul Monaf Chowdhury, Md Jubair Ahmed Sourov, and Md Mehedi HasanarXiv preprint arXiv:2511.12702, 2025Object counting has achieved remarkable success on visible instances, yet state-of-the-art (SOTA) methods fail under occlusion, a pervasive challenge in real world deployment. This failure stems from a fundamental architectural limitation where backbone networks encode occluding surfaces rather than target objects, thereby corrupting the feature representations required for accurate enumeration. To address this, we present CountOCC, an amodal counting framework that explicitly reconstructs occluded object features through hierarchical multimodal guidance. Rather than accepting degraded encodings, we synthesize complete representations by integrating spatial context from visible fragments with semantic priors from text and visual embeddings, generating class-discriminative features at occluded locations across multiple pyramid levels. We further introduce a visual equivalence objective that enforces consistency in attention space, ensuring that both occluded and unoccluded views of the same scene produce spatially aligned gradient-based attention maps. Together, these complementary mechanisms preserve discriminative properties essential for accurate counting under occlusion. For rigorous evaluation, we establish occlusion-augmented versions of FSC 147 and CARPK spanning both structured and unstructured scenes. CountOCC achieves SOTA performance on FSC 147 with 26.72% and 20.80% MAE reduction over prior baselines under occlusion in validation and test, respectively. CountOCC also demonstrates exceptional generalization by setting new SOTA results on CARPK with 49.89% MAE reduction and on CAPTUREReal with 28.79% MAE reduction, validating robust amodal counting across diverse visual domains. Code will be released soon.
@article{arib2025counting, title = {Counting Through Occlusion: Framework for Open World Amodal Counting}, author = {Arib, Safaeid Hossain and Akter, Rabeya and Chowdhury, Abdul Monaf and Sourov, Md Jubair Ahmed and Hasan, Md Mehedi}, journal = {arXiv preprint arXiv:2511.12702}, year = {2025}, url = {https://arxiv.org/abs/2511.12702}, } - ArXiv
 LAGEA: Language Guided Embodied Agents for Robotic ManipulationAbdul Monaf Chowdhury, Akm Moshiur Rahman Mazumder, Rabeya Akter, and Safaeid Hossain AribarXiv preprint arXiv:2509.23155, 2025
LAGEA: Language Guided Embodied Agents for Robotic ManipulationAbdul Monaf Chowdhury, Akm Moshiur Rahman Mazumder, Rabeya Akter, and Safaeid Hossain AribarXiv preprint arXiv:2509.23155, 2025Robotic manipulation benefits from foundation models that describe goals, but today’s agents still lack a principled way to learn from their own mistakes. We ask whether natural language can serve as feedback, an error reasoning signal that helps embodied agents diagnose what went wrong and correct course. We introduce LAGEA (Language Guided Embodied Agents), a framework that turns episodic, schema-constrained reflections from a vision language model (VLM) into temporally grounded guidance for reinforcement learning. LAGEA summarizes each attempt in concise language, localizes the decisive moments in the trajectory, aligns feedback with visual state in a shared representation, and converts goal progress and feedback agreement into bounded, step-wise shaping rewardswhose influence is modulated by an adaptive, failure-aware coefficient. This design yields dense signals early when exploration needs direction and gracefully recedes as competence grows. On the Meta-World MT10 embodied manipulation benchmark, LAGEA improves average success over the state-of-the-art (SOTA) methods by 9.0% on random goals and 5.3% on fixed goals, while converging faster. These results support our hypothesis: language, when structured and grounded in time, is an effective mechanism for teaching robots to self-reflect on mistakes and make better choices.
@article{chowdhury2025lagea, title = {LAGEA: Language Guided Embodied Agents for Robotic Manipulation}, author = {Chowdhury, Abdul Monaf and Mazumder, Akm Moshiur Rahman and Akter, Rabeya and Arib, Safaeid Hossain}, journal = {arXiv preprint arXiv:2509.23155}, year = {2025}, url = {https://arxiv.org/abs/2509.23155}, } - AAAI 26
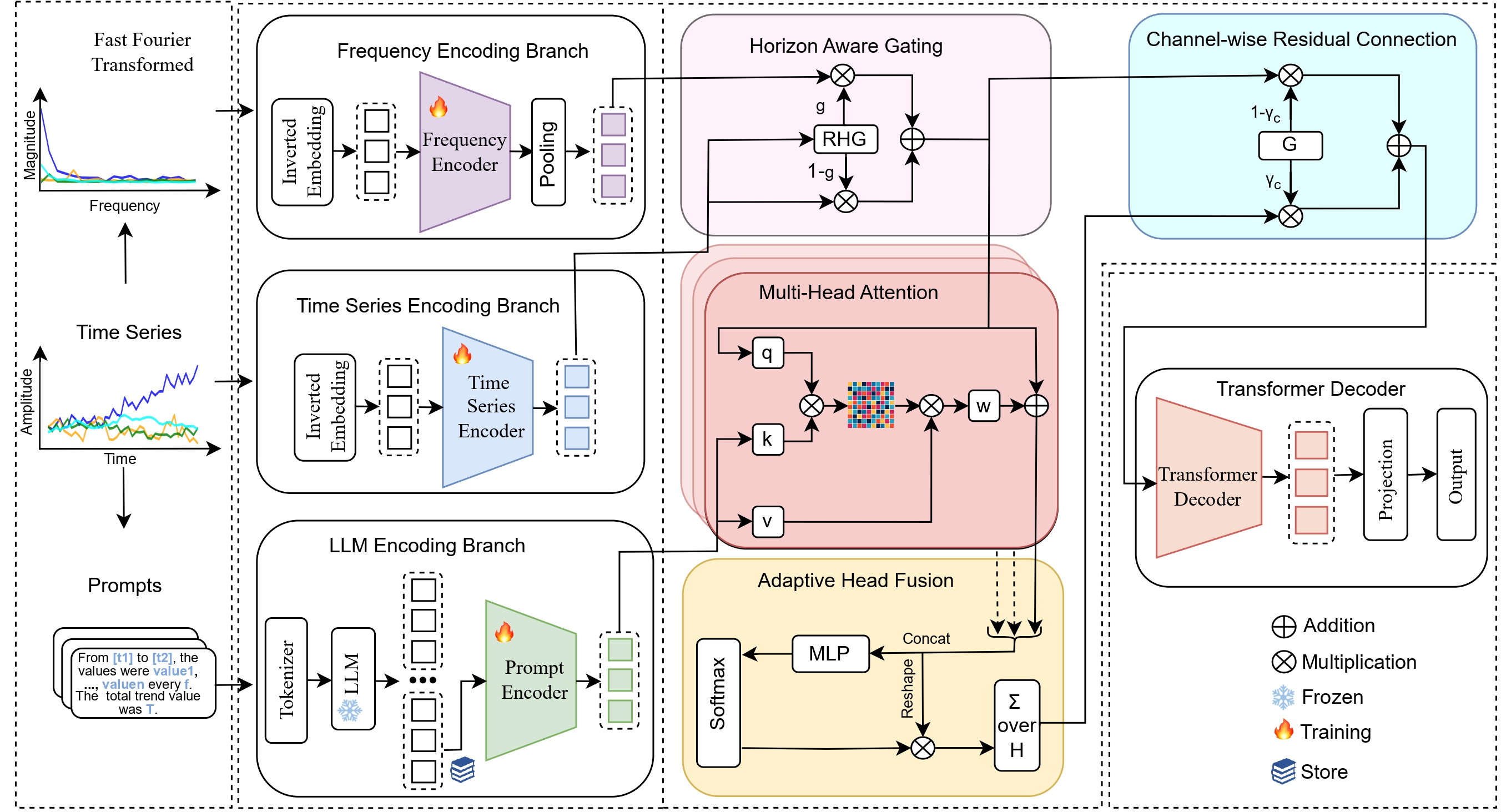 T3Time: Tri-Modal Time Series Forecasting via Adaptive Multi-Head Alignment and Residual FusionAbdul Monaf Chowdhury, Rabeya Akter, and Safaeid Hossain AribarXiv preprint arXiv:2508.04251, 2025
T3Time: Tri-Modal Time Series Forecasting via Adaptive Multi-Head Alignment and Residual FusionAbdul Monaf Chowdhury, Rabeya Akter, and Safaeid Hossain AribarXiv preprint arXiv:2508.04251, 2025Multivariate time series forecasting (MTSF) seeks to model temporal dynamics among variables to predict future trends. Transformer-based models and large language models (LLMs) have shown promise due to their ability to capture long-range dependencies and patterns. However, current methods often rely on rigid inductive biases, ignore intervariable interactions, or apply static fusion strategies that limit adaptability across forecast horizons. These limitations create bottlenecks in capturing nuanced, horizon-specific relationships in time-series data. To solve this problem, we propose T3Time, a novel trimodal framework consisting of time, spectral, and prompt branches, where the dedicated frequency encoding branch captures the periodic structures along with a gating mechanism that learns prioritization between temporal and spectral features based on the prediction horizon. We also proposed a mechanism which adaptively aggregates multiple cross-modal alignment heads by dynamically weighting the importance of each head based on the features. Extensive experiments on benchmark datasets demonstrate that our model consistently outperforms state-of-the-art baselines, achieving an average reduction of 3.28% in MSE and 2.29% in MAE. Furthermore, it shows strong generalization in few-shot learning settings: with 5% training data, we see a reduction in MSE and MAE by 4.13% and 1.91%, respectively; and with 10% data, by 3.62% and 1.98% on average.
@article{chowdhury2025t3time, title = {T3Time: Tri-Modal Time Series Forecasting via Adaptive Multi-Head Alignment and Residual Fusion}, author = {Chowdhury, Abdul Monaf and Akter, Rabeya and Arib, Safaeid Hossain}, journal = {arXiv preprint arXiv:2508.04251}, year = {2025}, url = {https://www.arxiv.org/abs/2508.04251}, }
2024
- Access
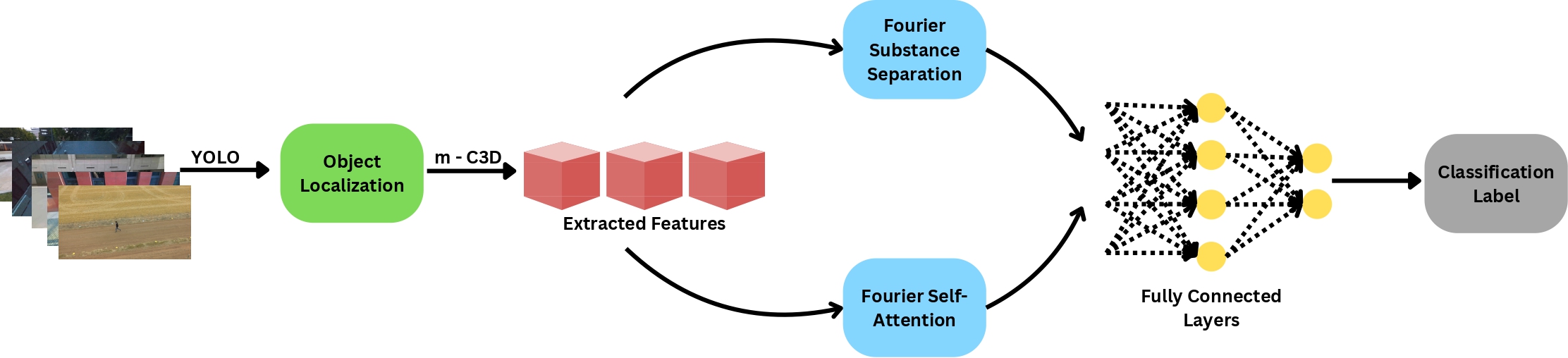 U-ActionNet: Dual-pathway fourier networks with region-of-interest module for efficient action recognition in UAV surveillanceAbdul Monaf Chowdhury, Ahsan Imran, Md Mehedi Hasan, Riad Ahmed, Akm Azad, and 1 more authorIEEE Access, 2024
U-ActionNet: Dual-pathway fourier networks with region-of-interest module for efficient action recognition in UAV surveillanceAbdul Monaf Chowdhury, Ahsan Imran, Md Mehedi Hasan, Riad Ahmed, Akm Azad, and 1 more authorIEEE Access, 2024Unmanned Aerial Vehicles (UAV) have revolutionized human action recognition by offering a bird’s-eye perspective, thereby unlocking unprecedented potential for comprehensive support within surveillance systems. This paper presents synergistic strategies for enhancing Human Action Recognition (HAR) in UAV imagery. Leveraging a dual-path approach, we propose a novel framework U-ActionNet that integrates FFT-based substance separation and space-time self-attention techniques to improve the accuracy and efficiency of HAR tasks. Catering the server side the first pathway employs a modified C3D model with Fast Fourier Transform (FFT)-based object movement and attention detection mechanisms to effectively extract human actors from complex scenes and capture spatiotemporal dynamics in UAV footage. Moreover, a generalized Region-of-Interest (ROI) module is utilized to concentrate on optimal regions to enhance target recognition. Through extensive experiments on the Drone Action and UAV-human datasets, we demonstrate the effectiveness of our approach, achieving superior performance compared to the state-of-the-art methods with Top-1 accuracies of 94.94% and 95.05%, respectively. Meanwhile, the second pathway employs edge-optimized models, integrating ROI extraction-based frame sampling technique to eliminate static frames while preserving pivotal frames essential for model training. We introduce a lightweight model named U-ActionNet Light which is a combination of MobileNetV2, Fourier module, and BiLSTM models that demand only one-ninth of the parameters compared to the server-side model. Demonstrating its efficacy, this model attains Top-1 accuracies of 80.43% and 84.74% on the same datasets, surpassing the baseline by a significant margin. Experimental results show that the presented frameworks are promising for surveillance, search and rescue, and activity monitoring, where accurate and real-time human action recognition from UAV platforms is essential.
@article{chowdhury2024u, title = {U-ActionNet: Dual-pathway fourier networks with region-of-interest module for efficient action recognition in UAV surveillance}, author = {Chowdhury, Abdul Monaf and Imran, Ahsan and Hasan, Md Mehedi and Ahmed, Riad and Azad, Akm and Alyami, Salem A}, journal = {IEEE Access}, year = {2024}, publisher = {IEEE}, }
2023
- STI
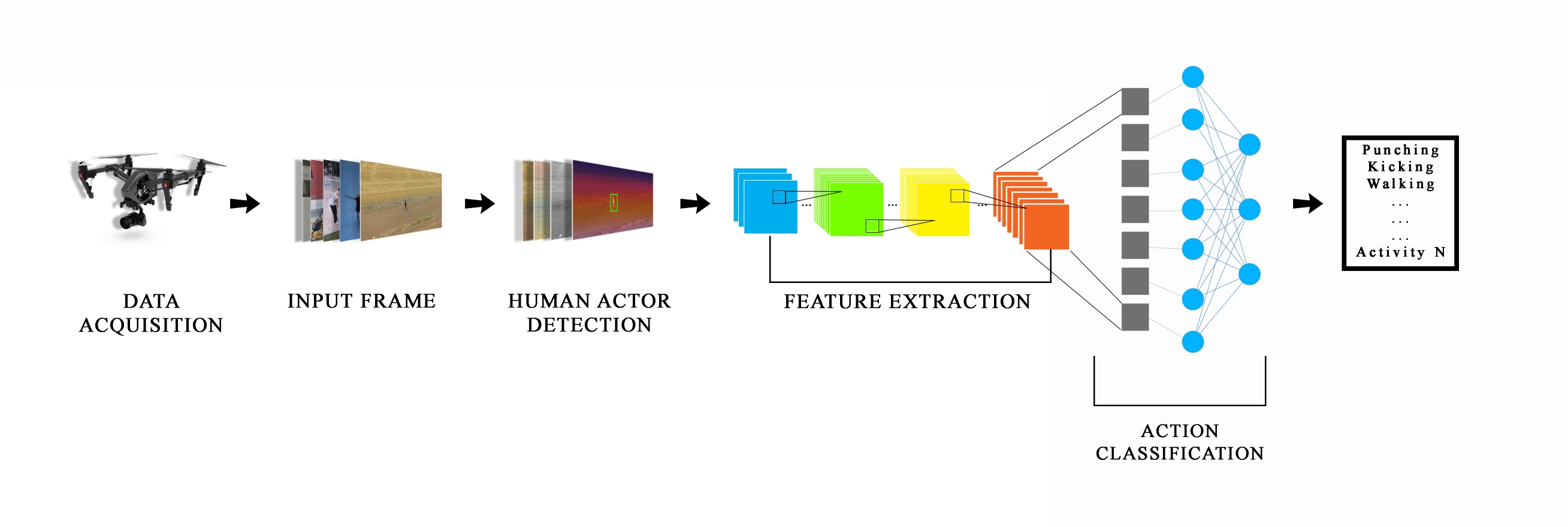 FFT-UAVNet: FFT Based Human Action Recognition for Drone Surveillance SystemAbdul Monaf Chowdhury, Ahsan Imran, and Md Mehedi HasanIn 2023 5th International Conference on Sustainable Technologies for Industry 5.0 (STI), 2023
FFT-UAVNet: FFT Based Human Action Recognition for Drone Surveillance SystemAbdul Monaf Chowdhury, Ahsan Imran, and Md Mehedi HasanIn 2023 5th International Conference on Sustainable Technologies for Industry 5.0 (STI), 2023Unmanned aerial vehicles (UAVs) have emerged as a transformative technology for human action recognition, providing a birds-eye view and unlocking new possibilities for precise and comprehensive support in surveillance systems. While substantial advances in ground-based human action recognition have been achieved, the unique characteristics of UAV footage present new challenges that require tailored solutions. Specifically, the reduced scale of humans in aerial perspectives necessitates the development of specialised models to accurately recognize and interpret human actions. Our research focuses on modifying the well-established C3D model and incorporating Fast Fourier Transform (FFT)-based object disentanglement (FO) and space-time attention (FA) mechanisms. By leveraging the power of FFT, our model effectively disentangles the human actors from the background and captures the spatio-temporal dynamics of human actions in UAV footage, enhancing the discriminative capabilities and enabling accurate action recognition. Through extensive experimentation on a subset of the UAV-Human dataset, our proposed FFT-UAVNet (m-C3D+FO&FA+FC) model demonstrates remarkable improvements in performance. We achieve a Top-1 accuracy of 64.86% and a Top-3 accuracy of 83.37%, surpassing the results obtained by the standard C3D and X3D methods, which achieve only a Top-1 accuracy of 28.05% and 31.33%, respectively. These findings underscore the efficacy of our approach and emphasize the significance of the proposed model for UAV datasets in maximizing the potential of UAV-based human action recognition.
@inproceedings{chowdhury2023fft, title = {FFT-UAVNet: FFT Based Human Action Recognition for Drone Surveillance System}, author = {Chowdhury, Abdul Monaf and Imran, Ahsan and Hasan, Md Mehedi}, booktitle = {2023 5th International Conference on Sustainable Technologies for Industry 5.0 (STI)}, pages = {1--6}, year = {2023}, organization = {IEEE}, }